前文实现了一个lucenne的全文检索,回顾一下我们的流程:
- 针对每个文档,构建一个文档对象。该文档对象里面用了不同的域,描述了该文档的信息,大小,内容。。。
- 将文档对象扔进索引库
- 将索引库,存放在本地磁盘
- 到磁盘的索引库目录下,创建了一个查询对象,查询条件是:指定内容分词进行查询,获取查询结果
这里对第一段代码进行继续介绍:第一段代码在构建域的时候,不同的域new Filed的子类不一样
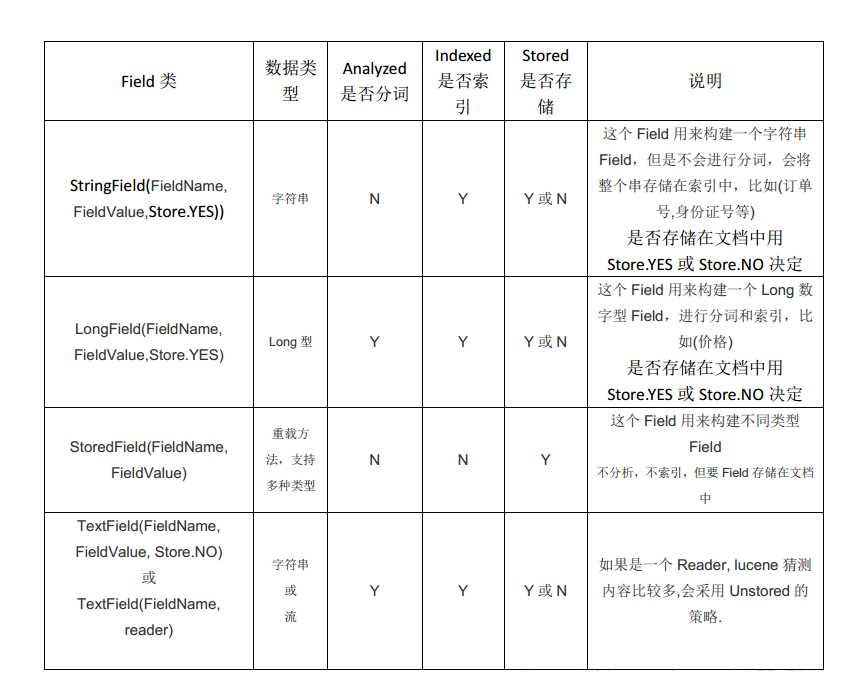
(1)是否分词
- 是:对该field存储的内容进行分词,分词的目的,就是为了索引。比如:文档的内容
- 否:不需要对field存储的内容进行分词,不分词,不代表不索引,而是将整个内容进行索引。比如:文件大小,文件路径,不需要分词
(2)是否索引
- 是:将分好的词进行索引,索引的目的,就是为了搜索
- 否:不索引,也就是不对该field域进行搜索
- 是否:就是指定扔进索引库的时候,对不对分的词创建索引
(3)是否存储
- 是:将field域中的内容存储到文档域中。存储的目的,就是为了搜索页面显示取值用的
- 否:不将field域中的内容存储到文档域中。不存储,则搜索页面中没法获取该field域的值
比如:Field fileContentField = new TextField("fileContent", file_content, Store.NO); 文件的内容没有进行储存,不能获取到





