
MQ的重试机制 由于MQ经常处于复杂的分布式系统中,考虑网络波动、服务宕机、程序异常因素,很有可能出现消息发送或者消费失败的问题。因此,消息的重试就是所有MQ中间件必须考虑到的一个关键点。如果没有消息重试,就可能产生消息丢失的问题,可能对系统产生很大的影响。所以,秉承宁可多发消息,也不可丢失消息的原
 2023-04-02
2023-04-02
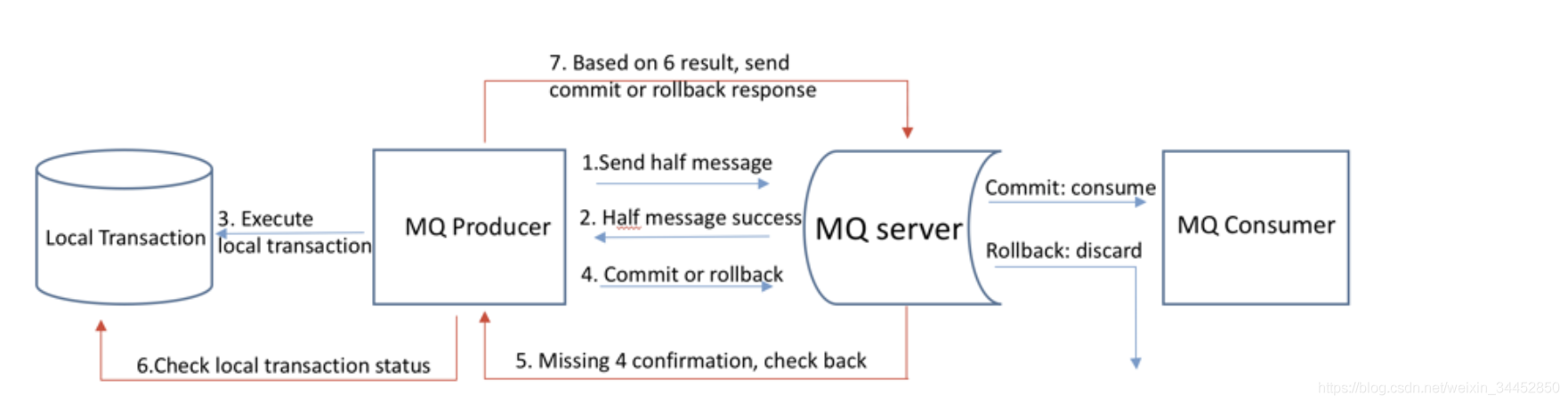
事务消息是RocketMQ提供的非常重要的一个特性,在4.x版本之后开源,可以利用事务消息轻松地实现分布式事务。本文对RocketMQ的事务消息进行详细介绍,并给出了代码示例。 相关概念 RocketMQ在其消息定义的基础上,对事务消息扩展了两个相关的概念: Half(Prepare) Mess
2023-04-02

RocketMQ的消息模式 在RocketMQ中,可以理解为没有ActiveMQ的createQueue()和createTopic()的用法,也就是并没有P2P和Pub/Sub类似的概念。RocketMQ不遵循JMS规范,而是使用了一套自定义的机制。可以理解为RocketMQ都是基于Pub/Sub
2023-04-02

七种模式介绍与应用场景 简单模式(Hello World) 做最简单的事情,一个生产者对应一个消费者,RabbitMQ相当于一个消息代理,负责将A的消息转发给B 应用场景:将发送的电子邮件放到消息队列,然后邮件服务在队列中获取邮件并发送给收件人 工作队列模式(Work queues) 在多个消
2023-04-02

介绍 实现zuul的动态路由可通过两种方式 基于配置中心实现配置文件动态刷新 基于数据库存储配置文件,发布RoutesRefreshedEvent事件,触发SimpleRouteLocator重新加载配置 代码参考:https://github.com/iyezhou/zuul-gateway-
2023-04-02

注意:如果Zuul网关应用注册到Eureka或Nacos,则会自动刷新路由配置,无需手动刷新 Nacos配置 routes: services: alipay: ok-cloud-service-alipay wechatpay: ok-cloud-service-wechat
2023-04-02

@Value,动态刷新 @ConfigurationProperties,需要添加apollo配置监听器@ApolloConfigChangeListener实现动态刷新 配置 pom.xml <dependency> <groupId>com.ctrip.fra
2023-04-02

elastic-job是当当开源的一款分布式定时作业框架。在这之前,我们开发定时任务一般都是使用quartz或者spring-task(ScheduledExecutorService),无论是使用quartz还是spring-task,我们都会至少遇到两个痛点: 不敢轻易跟着应用服务多节点部署,
2023-04-01

简介 Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 官网:http://kafka.apache.org/ 下载:http://kafka.apache.o
2023-04-01

基本概念 Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper。 分片 任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。 分片项与业务处理解耦 Ela
2023-04-01

RabbitMQ简介与安装 RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用。 (1)RabbitMQ基于Erlang,安装RabbitMQ前先要安装Erlang (2)RabbitMQ插件启动,通过启动此插件可以查看RabbitMQ的一些信
2023-04-01

Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。 即使是普通的服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得Kafka在日志处理等海量数据场景广泛应用
2023-04-01
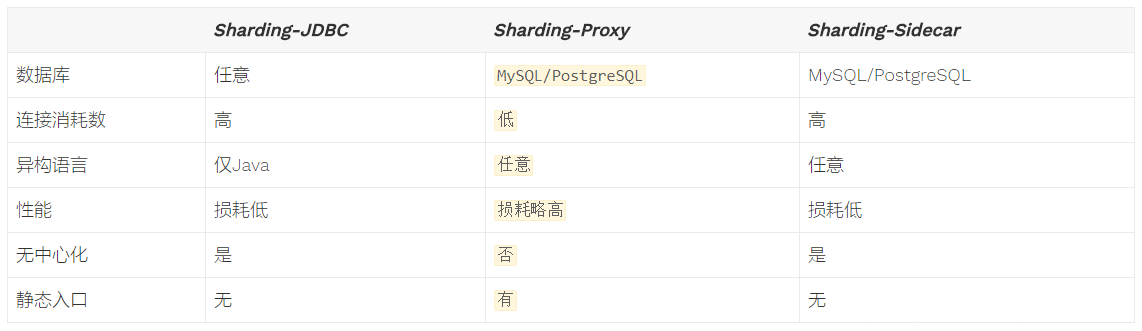
Sharding-Sphere说明 Sharding-Sphere提供3款产品,以下是其中两款 Sharding-JDBC 分库分表、读写分离(参考前两篇文章) Sharding-Proxy 分库分表、读写分离,它和mycat类似,属于中间件代理层,它类似一个数据库,代理后面的分库分表的多个数据库
2023-04-01

官方文档 GitHub的地址:https://github.com/apache/incubator-shardingsphere shardingsphere:https://github.com/apache/incubator-shardingsphere-example 中文文档地址:htt
2023-04-01
分享了 Sharding-JDBC 搭建读写分离,本章将用 Sharding-JDBC 实现分库分表功能 为什么要分库分表? 举个栗子:当单表数据量超过1000万后,查询的速度将会慢下来,利用索引,读写分离等优化,如果当数据量超过5000万时,一些常见的优化方法将失去作用,此时把单表水平划分到多库多
2023-04-01