
Java 全文搜索引擎框架 Lucene 毫无疑问,Lucene是目前最受欢迎的Java全文搜索框架,准确地说,它是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene为开发人员提供了相当完整的工具包,可以非常方便地实现强大的全文检索功能。下面有几款搜索引擎框架也是
 2023-05-03
2023-05-03

介绍 ProtoBuf 是google团队开发的用于高效存储和读取结构化数据的工具。什么是结构化数据呢,正如字面上表达的,就是带有一定结构的数据。比如电话簿上有很多记录数据,每条记录包含姓名、ID、邮件、电话等,这种结构重复出现。 XML、JSON 也可以用来存储此类结构化数据,但是使用Proto
2023-04-02

行为验证码(滑动拼图、点选文字),前后端(java)交互,包含vue/h5/Android/IOS/flutter/uni-app的源码和实现 后端基于Java实现,提供纯Java.jar和SpringBoot Starter。前端提供了Android、iOS、Futter、Uni-App、Reac
2023-04-02

Call Payment API from APP:https://pay.weixin.qq.com/wiki/doc/api/wxpay/en/pay/In-AppPay/chapter6_3.shtml APP Payment Development Guide:https://pay.wei
2023-04-02

官方文档 Hosted Payment SDK: https://shopify.dev/docs/hosted-payment-sdk/getting-started 参考:https://shopify.dev/tutorials/add-order-management-to-hosted-
2023-04-02

线性代数与矩阵 线性代数:线性代数中的基本量指的是向量,基本关系是严格的线性关系。也就是可以简单的将线性代数理解为向量与向量之间的线性关系的映射。 矩阵:描述线性代数中线性关系的参数,即矩阵是一个线性变换,可以将一些向量转换为另一些向量。 矩阵表示:数域$F$中$m \ast n$个数排成$m$行
2023-04-02

方向导数 方向导数定义 定理:若函数$f(x,y,z)$在点$P(x,y,z)$处可微,沿任意方向$l$的方向导数 $$ \frac{\partial f}{\partial l} = \frac{\partial f}{\partial x} \cos \alpha + \frac{\partia
2023-04-02

定积分定义 设函数$f(x)$定义在$[a,b]$上,若对$[a,b]$的任一种分法$a=x_0<x_1<x_2<···<x_n=b$,令$\Delta x_i=xi-x{i-1}$,任取$\xi_i \in [xi,x{i-1}]$,只要$\lambda = \max_{1
2023-04-02

Taylor公式 Taylor(泰勒)公式 Taylor(泰勒)公式是用一个函数在某点的信息描述其附近取值的公式。如果函数足够平滑,在已知函数在某一点的各阶导数值的情况下,Taylor公式可以利用这些导数值来做系数构建一个多项式近似函数在这一点的邻域中的值。 若函数f(x)在包含x_0的某个闭区间
2023-04-02

函数单调性 通过函数的导数的值,可以判断出函数的单调性、驻点以及极值点: 若导数大于0,则单调递增;若导数小于0,则单调递减;导数等于0的点为函数驻点。 如果函数的导函数在某一个区间内恒大于0(或恒小于0),那么函数在这一个区间单调递增(或单调递减),这种区间就叫做单调区间。 函数的驻点和不可导点
2023-04-02

导数的定义 设函数$y=f(x)$在点$x_0$的某邻域内有定义,若 $$ \lim \limits_{x \to x_0} \frac{f(x)-f(x_0)}{x-x0} = \lim \limits{\Delta x \to 0} \frac{\Delta y}{\Delta x} $$ 存
2023-04-02

函数的极限 1、自变量趋于有限制$x_0$时函数的极限 (1)$x \rightarrow x_0$ (2)$x \rightarrow x_0^+$ (3)$x \rightarrow x_0^-$ 2、自变量趋于无穷大时函数的极限 (1)$x \rightarrow
2023-04-02

数列极限的定义 设$\{x_n\}$为一数列,若有常数$a$,对任意给定的正数$\varepsilon$(无论$\varepsilon$有多小),总存在正整数$N$,使当$n>N$时,不等式$|x_n-a|<\varepsilon$恒成立,则称$a$是数列$\{x_n\}$的极限或称$\
2023-04-02

独立重复试验 独立重复试验的基本特征: 1、每次试验是在同样条件下进行 2、每次试验都是只有两种结果:发生与不发生 3、各次试验中的事件是相互独立的 4、每次试验,某事件发生的概率是相同的 二项分布 在$n$次独立重复试验中,设事件$A$发生的次数是$X$,且在每次试验中事件$A$发生的概率是$p
2023-04-02
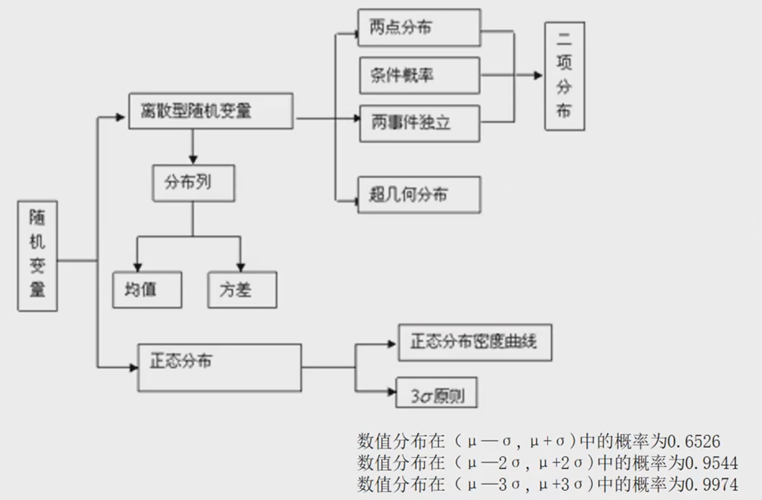
基本概念 若随机变量$X$服从一个数学期望为$μ$、方差为$σ^2$的正态分布,记为$N(μ,σ^2)$。其概率密度函数为正态分布的期望值$μ$决定了其位置,其标准差$σ$决定了分布的幅度。当$μ = 0, σ = 1$时的正态分布是标准正态分布。 离散型随机变量 (1)随机变量:如果随机试验的
2023-04-02