
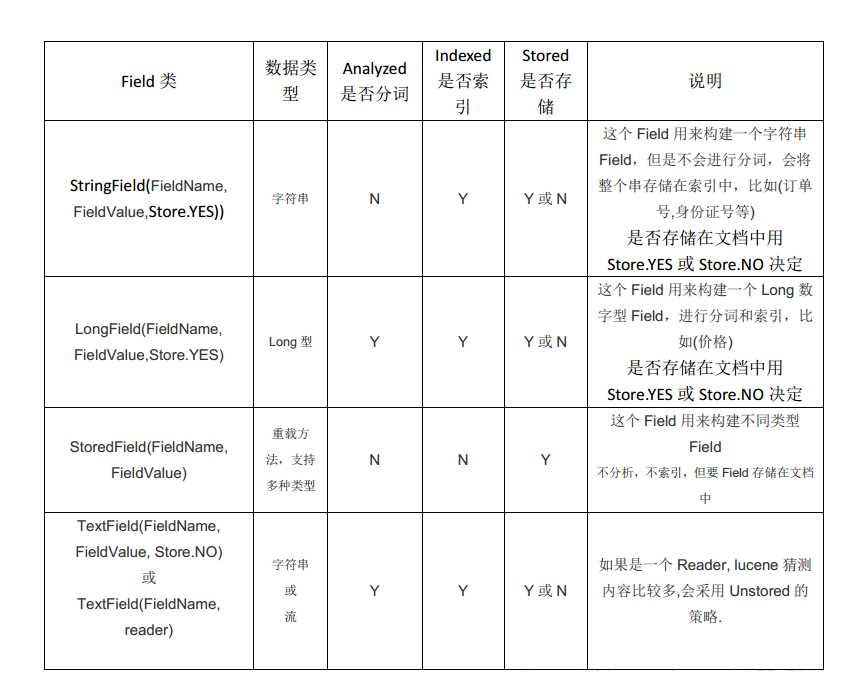
Lucene实现全文检索的流程 ① 绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容、采集文档、创建文档、分析文档、索引文档 ② 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面、创建查询、执行搜索,从索引库搜索引擎渲染搜索结
 2023-05-04
2023-05-04

为了减少代码量,写一个公用的增删改公用的获取IndexWriter对象的方法 /** * 增删改公用的获取IndexWriter对象 * @return * @throws Exception */ public IndexWriter getIndexWriter() throws Exc
2023-05-04
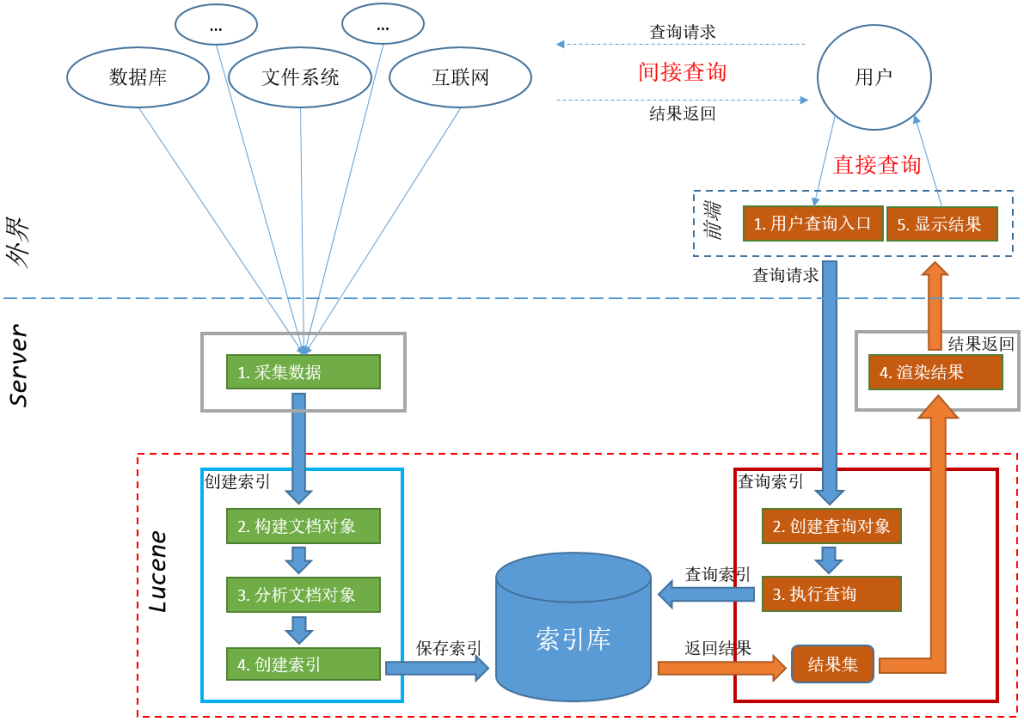
前文实现了一个lucenne的全文检索,回顾一下我们的流程: 针对每个文档,构建一个文档对象。该文档对象里面用了不同的域,描述了该文档的信息,大小,内容。。。 将文档对象扔进索引库 将索引库,存放在本地磁盘 到磁盘的索引库目录下,创建了一个查询对象,查询条件是:指定内容分词进行查询,获取查询结果
2023-05-03

需求:通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来:下图(是一堆文件列表) pom.xml <dependency> <groupId>org.apache.lucene</groupId> <artifactId&g
2023-05-03
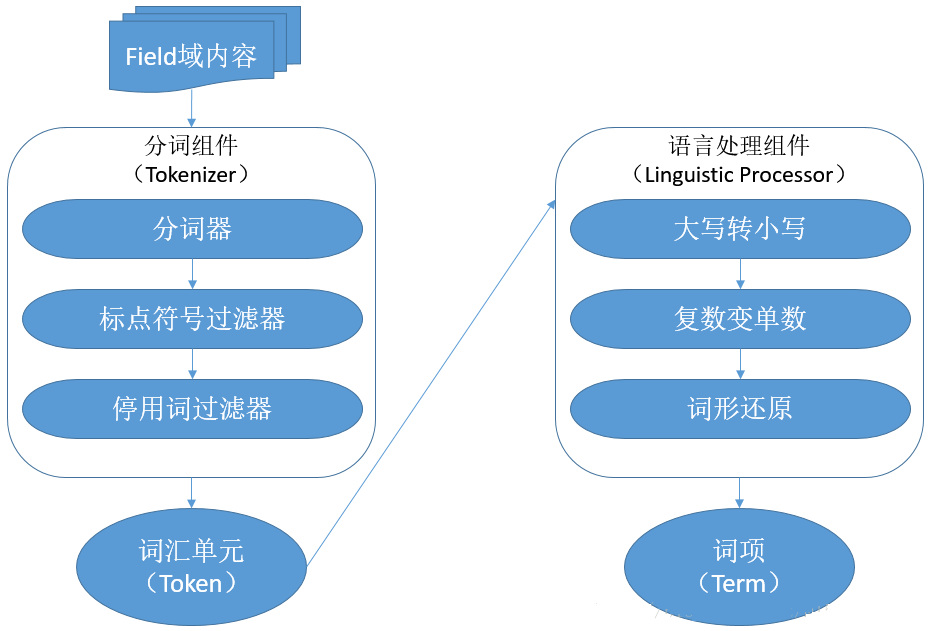
Lucene创建索引—分词,分词主要介绍这几个问题 分词是什么? 分词干嘛? 分词怎么分? 例如:我们能找到aaabbb.txt文档,但是不能找到aaabbb文档,好像说明fileName只能进行精确匹配。但是不能找到XXXX.txt文档,说明不是精确匹配,而是在索引库中全文检索.txt
2023-05-03
既然Lucene是实现全文检索,那么明白以下几个问题, Lucene是什么? Lucene实现全文检索的流程? 索引到底是如何创建的?(Indexing) 索引里面存放的又是什么东西? 搜索的的时候又是如何去查找索引的?(Search) 这5个问题搞明白了,那么lucene就算入门了。 1:lu
2023-05-03

需求场景提出 1:在指定(10个)不同名字,不同内容的word文档中,进行任意指定搜索。比如:搜索哪个文档中有:“高富帅”、“吃鸡”、”read”…等词汇 2:站内搜索:搜索任意关键词,出来相关内容。论坛,贴吧,淘宝 3:百度类似的搜索 4:智联招聘的搜索 分析 常规的搜索,我们是对数据库的内容
2023-05-03